Cách Tiết Kiệm Token Khi Làm Việc Với AI
Mỗi lần bạn gửi tin nhắn cho AI, bạn đang tiêu tiền - hoặc quota. Token là đơn vị tính phí của AI, và nếu không hiểu cách nó hoạt động, bạn sẽ đốt chi phí vào những thứ không cần thiết. Bài này breakdown từ cơ chế đến tips thực tế để làm việc với AI hiệu quả hơn mà tốn ít token hơn.
Dù bạn đang dùng Claude, ChatGPT, hay Gemini - tất cả đều tính phí theo token. Vấn đề là hầu hết mọi người không biết token ăn từ đâu ngoài phần tin nhắn họ tự gõ. Thực tế, system prompt, lịch sử hội thoại, file đính kèm, và thậm chí cả “phần suy nghĩ” của AI đều ngốn token ngầm mà bạn không hay.
Bài này dành cho ai? Nếu bạn vẫn còn dư nhiều usage và chưa bao giờ thấy quota vượt 50% - cứ dùng thoải mái, chưa cần lo. Nhưng nếu bạn đang nhận ra mình lúc nào cũng trên 70% usage trong ngày làm việc, hoặc bắt đầu có nhiều routine cần chạy tự động hơn, thêm client, công việc tăng theo cấp số nhân - thì việc tối ưu hóa token không phải “tiết kiệm cho có”. Đó là kỹ năng nên làm quen và thực tập ngay từ bây giờ, trước khi nó thực sự trở thành bottleneck.
Token là gì và tại sao nó quan trọng?
Token là đơn vị nhỏ nhất mà AI xử lý - không phải từ, không phải ký tự, mà là “mảnh” văn bản. Quy tắc thông dụng: 1.000 tokens xấp xỉ 750 từ tiếng Anh (tiếng Việt thường tốn nhiều token hơn vì ký tự dài hơn).
Context window là tổng số token AI có thể “nhìn thấy” trong một lần xử lý - bao gồm cả input và output. Vượt giới hạn này, AI sẽ “quên” phần đầu cuộc trò chuyện.
 Context window là “vùng nhìn” của AI - mọi thứ nằm ngoài vùng này sẽ bị lãng quên
Context window là “vùng nhìn” của AI - mọi thứ nằm ngoài vùng này sẽ bị lãng quên
Điều nhiều người không biết: AI phải đọc lại toàn bộ lịch sử hội thoại mỗi khi bạn gửi tin nhắn mới. Chat 100 tin nhắn dài = 100 lần đọc lại toàn bộ. Đây là lý do tại sao chat dài càng lúc càng đắt.
Giá API thực tế: Token đang cost bao nhiêu?
Hiểu pricing là bước đầu tiên để tiết kiệm. Các nhà cung cấp tính giá theo $ / 1 triệu token (MTok), với input và output tính riêng.
 Chi phí API Anthropic - hiểu rõ pricing giúp bạn chọn đúng model cho từng task
Chi phí API Anthropic - hiểu rõ pricing giúp bạn chọn đúng model cho từng task
Bảng giá Claude (2026):
| Model | Input ($/MTok) | Output ($/MTok) |
|---|---|---|
| Claude Haiku 4.5 | $1.00 | $5.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| Claude Opus 4.7 | $5.00 | $25.00 |
| Claude Opus 4.7 Fast Mode | $30.00 | $150.00 |
Để so sánh - OpenAI:
| Model | Input ($/MTok) | Output ($/MTok) |
|---|---|---|
| GPT-5.4 | $2.50 | $15.00 |
| GPT-4o mini | ~$0.15 | ~$0.60 |
Lưu ý thực tế: Anthropic báo cáo chi phí trung bình ~$13/developer/ngày làm việc, và $150-250/tháng cho enterprise. 90% users dưới $30/ngày. Nhưng không có gì ngăn bạn vượt con số đó nếu không quản lý tốt.
Chi phí ẩn không ai nói: Output tokens đắt gấp 3-5 lần input. Có nghĩa là câu trả lời dài = đắt hơn nhiều so với câu hỏi dài. Và extended thinking (phần “suy nghĩ” của AI trước khi trả lời) cũng được tính như output tokens - có thể ngốn hàng chục nghìn tokens mỗi request.
Điều gì thực sự ăn token?
Ngoài tin nhắn bạn gõ, còn có:
- System prompt: ~4.200 tokens, load tự động mỗi session
- Toàn bộ lịch sử hội thoại: Mỗi message mới = AI đọc lại TẤT CẢ
- File đính kèm: PDF, ảnh, document - đặc biệt nếu gửi nguyên file không xử lý trước
- CLAUDE.md / Custom instructions: Load vào context mỗi session, dù liên quan hay không
- MCP tool schemas: Các tool definition chiếm không gian context
- Extended thinking: Token “suy nghĩ ngầm” tính như output
Tips tiết kiệm token - Cho người dùng thường
1. Convert PDF/DOCX thành text trước khi gửi
PDF chứa metadata, font embedding, formatting - chiếm token không có giá trị. Thay vì upload nguyên file:
- Copy phần text cần thiết ra rồi paste
- Dùng ChatPDF, PDF2MD để chuyển sang markdown
- Mac: Preview -> chọn tất cả -> copy text
Cùng nội dung đó, plain text sẽ nhẹ hơn PDF 30-60% => Tiết kiệm token hơn
2. Chỉ gửi phần liên quan - không phải cả file
Thay vì: “Đây là báo cáo 50 trang, phân tích giúp tôi” Nên làm: Paste đúng section liên quan (trang 12-15) + câu hỏi cụ thể.
3. Tạo “Context File” cho project thường dùng
Mỗi khi bắt đầu chat mới, thay vì giải thích lại từ đầu, tạo sẵn file:
# Context - [Tên Project]
## Tôi là ai: [Role, công ty, vị trí]
## Project: [Mục tiêu, constraints]
## Tone tôi muốn: [ngắn gọn / bullet / tiếng Việt]
## Session trước: [Đã làm gì, đang dở đâu]Paste file này vào đầu mỗi chat mới. Tiết kiệm 10-20 tin nhắn giải thích.
4. Lưu output AI thành file markdown
Sau mỗi session quan trọng:
“Tóm tắt những gì chúng ta đã làm hôm nay thành 1 file markdown ngắn gọn để tôi dùng lần sau”
Lưu file đó lại. Lần sau paste vào thay vì giải thích lại từ đầu. Chi phí: 500 tokens lần sau thay vì 5.000 tokens giải thích.
Mình có viết guide chi tiết hơn về cách setup cái này tự động - kể cả cách để AI tự lưu log vào local drive sau mỗi session: Optimize AI Chat History: Tự động lưu log, giữ context, tiết kiệm token.
5. Bắt đầu chat mới khi đổi chủ đề
Chat marketing 200 tin nhắn mà hỏi 1 câu về HR = AI đọc 200 tin nhắn marketing không liên quan trước khi trả lời. Mỗi topic = 1 chat mới.
6. Prompt cụ thể và xóa filler
| Thay vì | Dùng |
|---|---|
| ”Bạn có thể giúp tôi…” | Thẳng vào yêu cầu |
| ”Như bạn đã biết từ cuộc trò chuyện trước…” | Paste context file |
| ”Hãy suy nghĩ kỹ và…” | Bỏ - AI tự làm |
| ”Cảm ơn, bây giờ…” | Bỏ phần lịch sự |
Thêm output format ngay trong prompt: “Trả về 3 bullet, mỗi bullet 1 dòng” - AI không sinh text thừa.
7. Reset chat dài bằng summary
Khi chat đã quá dài:
- Bảo AI: “Tóm tắt cuộc trò chuyện này thành 10 bullet points”
- Copy summary
- Mở chat mới + paste summary
- Tiếp tục
Từ 50.000 tokens lịch sử xuống còn ~500 tokens summary.
Tips tiết kiệm token - Cho developer / Claude Code
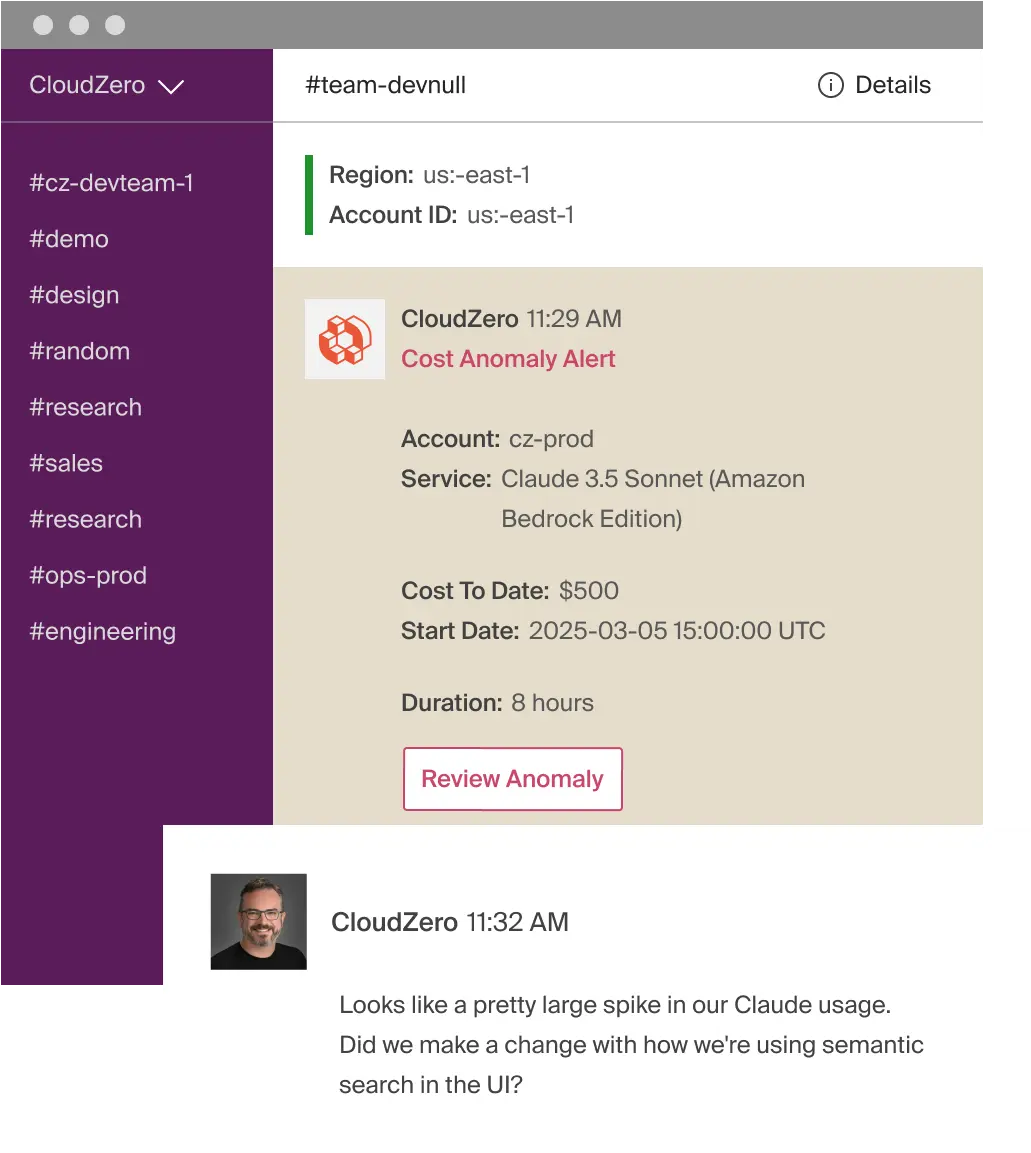 Spike cost thực tế: $500 trong 8 giờ cho Claude API - điều này xảy ra khi không có kiểm soát token
Spike cost thực tế: $500 trong 8 giờ cho Claude API - điều này xảy ra khi không có kiểm soát token
8. /clear thường xuyên giữa task
Lịch sử cũ không liên quan là rác thuần túy - ăn token mỗi message. Dùng /rename để lưu session tên có nghĩa, rồi /clear bắt đầu lại sạch.
9. Plan Mode trước khi code
Nhấn Shift+Tab để vào Plan Mode - AI phân tích và đề xuất approach, bạn approve rồi mới chạy. Tránh scenario “làm sai - undo - làm lại” - mỗi lần làm lại là token đốt thêm. Nếu AI đang đi sai: nhấn Escape ngay.
10. Chọn đúng model cho từng task
| Task | Model nên dùng |
|---|---|
| Câu hỏi đơn giản, format, grep | Haiku |
| Hầu hết coding tasks | Sonnet (default) |
| Architecture decisions, reasoning phức tạp | Opus |
Dùng /model để switch mid-session. Chênh lệch Haiku vs Opus là 25 lần về input, 5 lần về output.
11. Tắt/giảm Extended Thinking cho task đơn giản
Extended thinking mặc định bật và ngốn hàng chục nghìn tokens/request. Với task đơn giản:
MAX_THINKING_TOKENS=8000 # Giảm budget
# hoặc /effort low trong session
# hoặc tắt qua /config12. Giữ CLAUDE.md dưới 200 dòng - chuyển workflows vào Skills
CLAUDE.md load toàn bộ vào context mỗi session dù task có liên quan hay không. Skills chỉ load khi gọi. Di chuyển hướng dẫn workflow cụ thể (PR review, DB migration…) sang skills - giữ CLAUDE.md chỉ với essentials.
13. Hooks để filter data trước khi AI đọc
Thay vì để AI đọc log file 10.000 dòng:
# Hook filter trước: từ 50.000 tokens xuống còn vài trăm
cmd 2>&1 | grep -A 5 -E "(FAIL|ERROR)" | head -100Preprocessing = tiết kiệm nhất cho các task data-heavy.
Câu hỏi thường gặp (FAQ)
1 triệu tokens là bao nhiêu chữ thực tế?
Khoảng 750.000 từ tiếng Anh - tương đương 3-4 cuốn sách trung bình. Với tiếng Việt, con số này thấp hơn khoảng 20-30% do ký tự dài hơn. Với Claude Sonnet 4.6 ở giá $3/MTok input, 1 triệu tokens input sẽ tốn $3 - nghe có vẻ rẻ, nhưng output đắt gấp 5 lần ($15/MTok), và trong thực tế bạn send/receive nhiều lần.
Dùng subscription (Claude Pro/Max) thì có cần quan tâm token không?
Vẫn cần. Subscription có giới hạn usage (rate limit) tính theo khoảng thời gian. Nếu bạn đốt nhiều token, bạn sẽ bị throttle (chậm hoặc tạm dừng) sớm hơn trong ngày. Tips tiết kiệm token áp dụng cho cả subscription lẫn API pay-per-use.
Ảnh tốn bao nhiêu tokens?
Tùy resolution và model. Với Claude, một ảnh 1080p có thể tốn 1.500-2.000 tokens chỉ để “đọc”. Nếu bạn gửi ảnh chỉ để AI đọc text trong đó, tốt hơn là crop chỉ phần chứa text, hoặc dùng OCR để extract text rồi paste text vào thay ảnh.
Prompt caching là gì và giúp tiết kiệm thế nào?
Prompt caching là tính năng API cho phép “cache” phần system prompt hoặc context cố định - lần sau gọi lại phần đó chỉ tốn 10% giá bình thường. Với Anthropic, cache hit discount là 90%. Tính năng này chủ yếu hữu ích cho developers build app, không phải người dùng cuối thông thường.
Tổng kết
Token = tiền, và phần lớn token bị lãng phí vào những thứ không cần thiết: lịch sử hội thoại dài, file gửi nguyên không xử lý, prompt mơ hồ, và model “xịn” dùng cho task đơn giản. Hai thay đổi có impact ngay lập tức nhất: tạo context file để tái sử dụng (giảm token giải thích) và bắt đầu chat mới theo topic (tránh AI đọc lại lịch sử không liên quan). Áp dụng các tips trong bài này có thể giảm 30-60% token usage mà không ảnh hưởng chất lượng output.
Liên kết
- Context trong AI: Chìa khóa để biến AI từ “người lạ” thành “cộng sự”
- Optimize AI Chat History: Tự động lưu log, giữ context, tiết kiệm token
- Viết Prompt Có Cấu Trúc: Framework RTFC
- Claude Projects là gì? Workspace AI cho người dùng thực chiến
- ccusage & codeburn: Theo dõi lịch sử và chi phí dùng Claude Code