Two AI models, nearly identical benchmark scores. One costs $15 per million input tokens. The other costs $2.50. The cheaper one isn’t from a US lab.
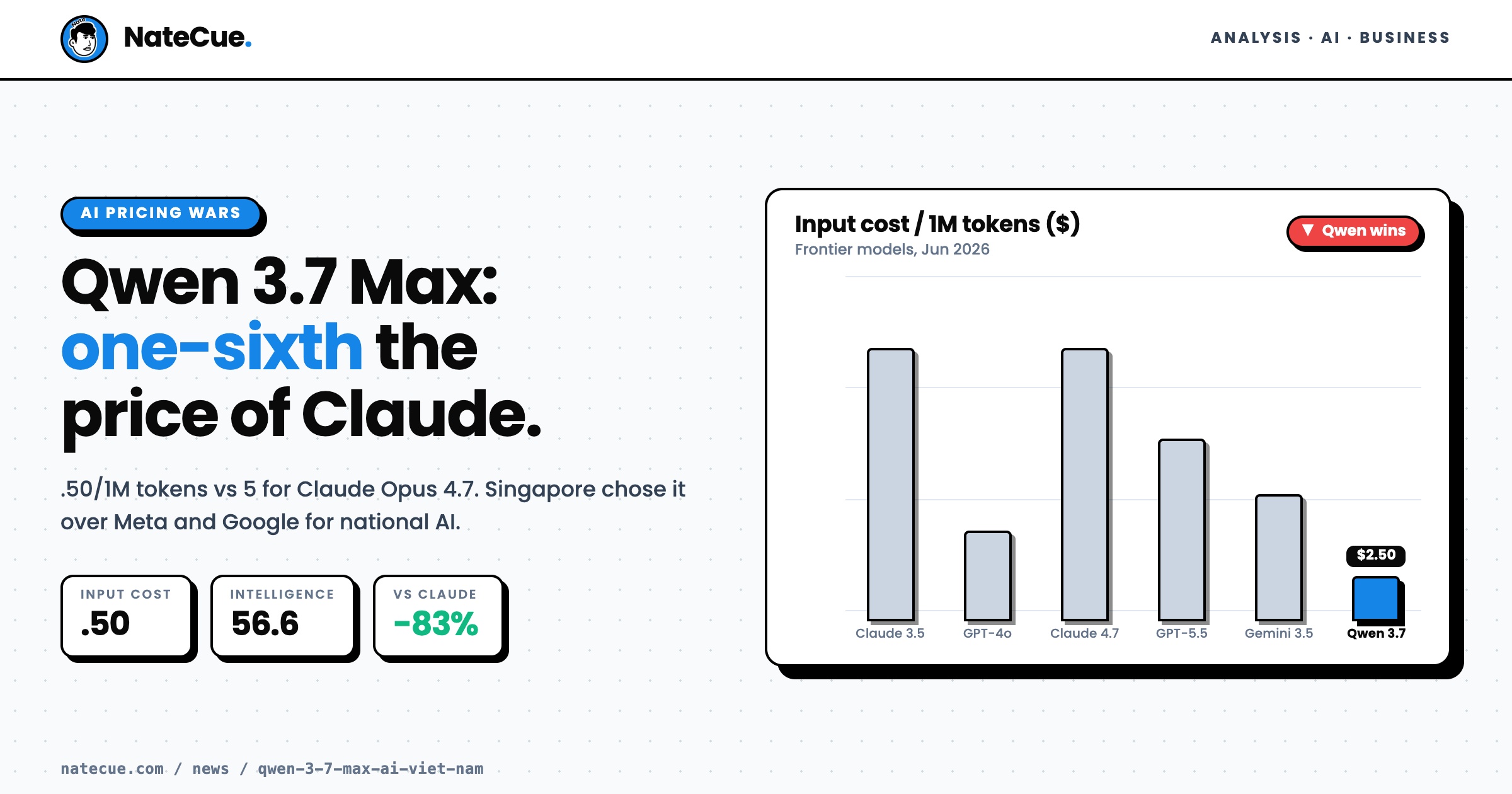
In June 2026, Alibaba unveiled Qwen 3.7 Max at its inaugural conference in Singapore. The model scores 56.6 on the Intelligence Index - trailing Claude Opus 4.7 (57.3) and GPT-5.5 (60.2) by just 1-3 points (AI Tool Bolt, 2026). On price, the gap is 6x.

What Makes Qwen 3.7 Max Different
Qwen 3.7 Max is Alibaba’s new flagship, with over 1 trillion parameters and a 1M-token context window - on par with Claude Opus 4.8 and GPT-5.5. The technical specs aren’t the headline. The commercial specs are:
- API pricing: $2.50/1M input tokens, $7.50/1M output. Claude Opus 4.7 charges $15/$75. GPT-5.5 charges $10/$30.
- Autonomous operation: Runs continuously for 35 hours without performance degradation (Alibaba Cloud, 2026).
- Anthropic API compatible: Drop-in replacement for Claude - no code changes required.
- 119 languages native: Including Vietnamese, with specific fine-tuning on Southeast Asian language data.
On SWE-Bench Pro - the benchmark testing real-world coding tasks rather than synthetic puzzles - Qwen 3.7 Max outperforms GPT-5.5 (oFox AI, 2026). This isn’t an imitation model. It’s a real competitor.
Singapore’s National AI Choice - and What It Signals
Singapore selected Qwen over Meta Llama and Google Gemma to power its national AI program. That’s a pragmatic decision by a small nation building AI infrastructure without full dependency on US Big Tech.
The ecosystem build matters: Alibaba Cloud, NTUC’s Tech Talent Assembly, and ST Telemedia Global Data Centres jointly committed to equipping 1,000+ SMEs and students with generative and agentic AI skills starting June 2026. Qwen isn’t just an API play - it’s a full regional stack strategy.
Sea-Lion, the ASEAN-focused model built on Qwen, was trained on an additional 100 billion Southeast Asian language tokens, with Vietnamese among the priority languages. That’s not a localization afterthought - it’s structural investment in the region.
The Cost Math for Southeast Asia Businesses
Most startups and agencies in Vietnam and Southeast Asia run AI workflows on OpenAI or Anthropic. At 10 million tokens per month - a reasonable volume for a mid-size content or automation team - monthly API costs break down as:
- Claude Opus 4.7: ~$150 (input) + $750 (output) = $900/month
- Qwen 3.7 Max: ~$25 (input) + $75 (output) = $100/month
Nine times cheaper. For near-equivalent output on most production tasks.
This is why engineering teams across Southeast Asia are quietly re-evaluating their AI stack. The benchmark gap doesn’t justify a 9x cost premium for most workflows.
Where the Gap Still Matters
Two honest caveats.
The performance delta is real, if narrow. GPT-5.5 and Claude Opus 4.8 still lead on complex multi-step reasoning. The 56.6 vs 60.2 Intelligence Index gap is small in aggregate, but can matter in production workflows requiring nuanced judgment rather than efficient processing.
Second: compliance and data sovereignty. Enterprises in finance, healthcare, or those handling US/EU customer data under regulatory frameworks may face restrictions using Chinese-developed AI infrastructure. That’s not a solved problem.
For the majority of production use cases - content generation, automation, data analysis, customer support workflows - the performance gap isn’t wide enough to justify a 6-9x price premium. This is the moment to evaluate your stack, not necessarily replace it entirely.
NateCue's Take
The detail that matters most: Qwen 3.7 Max is fully compatible with the Anthropic API. You swap Claude out, drop Qwen in - no code rewrite. That's a competitive moat being quietly dismantled. For teams in Vietnam and Southeast Asia evaluating AI spend, the ROI calculus has fundamentally shifted. Qwen's native Vietnamese support plus frontier-competitive performance makes it the practical answer for most production workflows. But lower price doesn't automatically mean right choice - use cases requiring US compliance frameworks or deep Anthropic ecosystem integration still need Western models. The smart play is a two-track stack: Qwen for volume tasks, premium models for where the gap actually matters.